AI Literacy 101
Congressional Briefing
Ariel Fogel
November 5, 2025

Let's watch an LLM in action
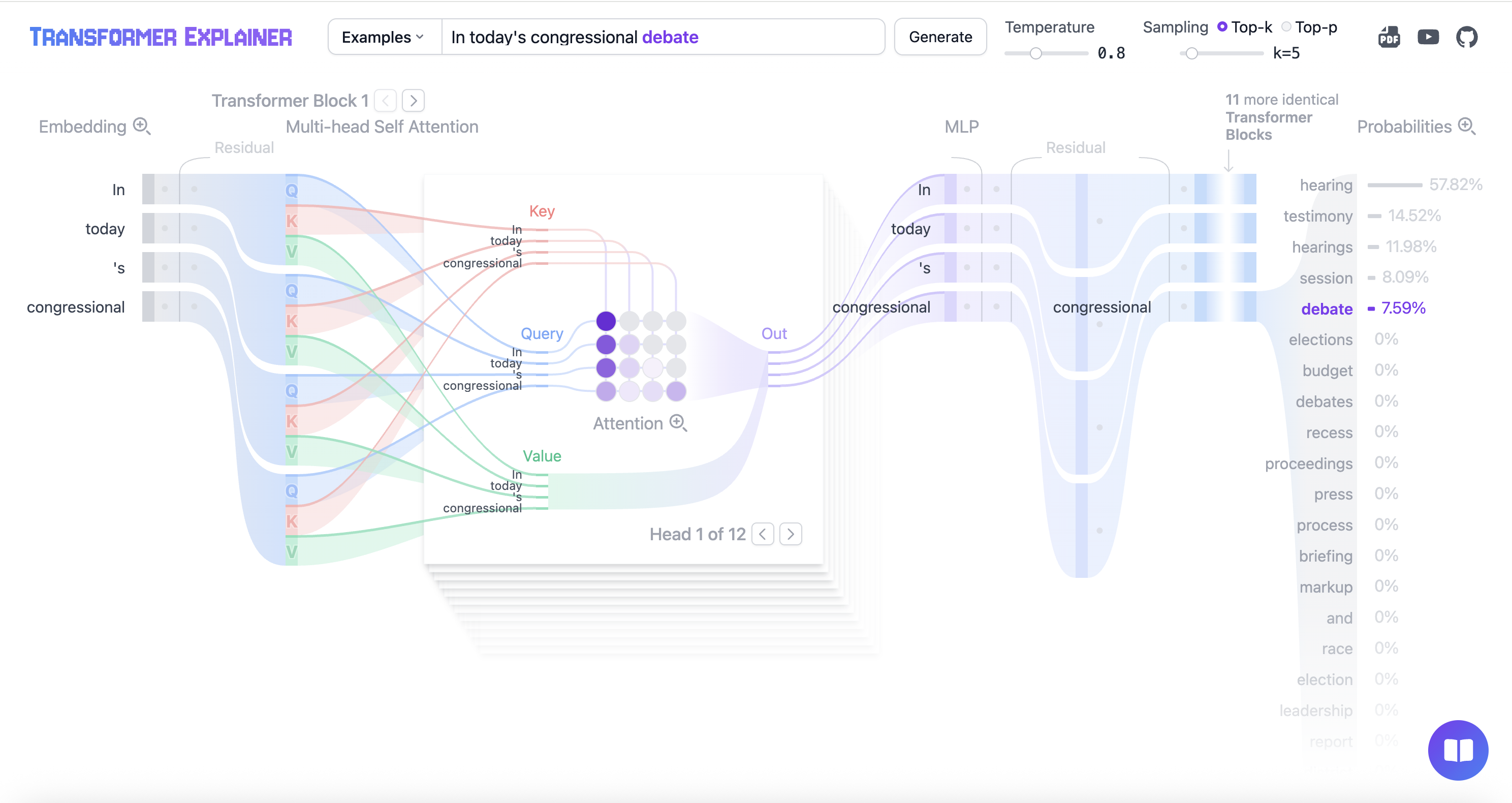
Prompt: "In today's congressional…"
The model picked "debate"

But "briefing" got 0% probability
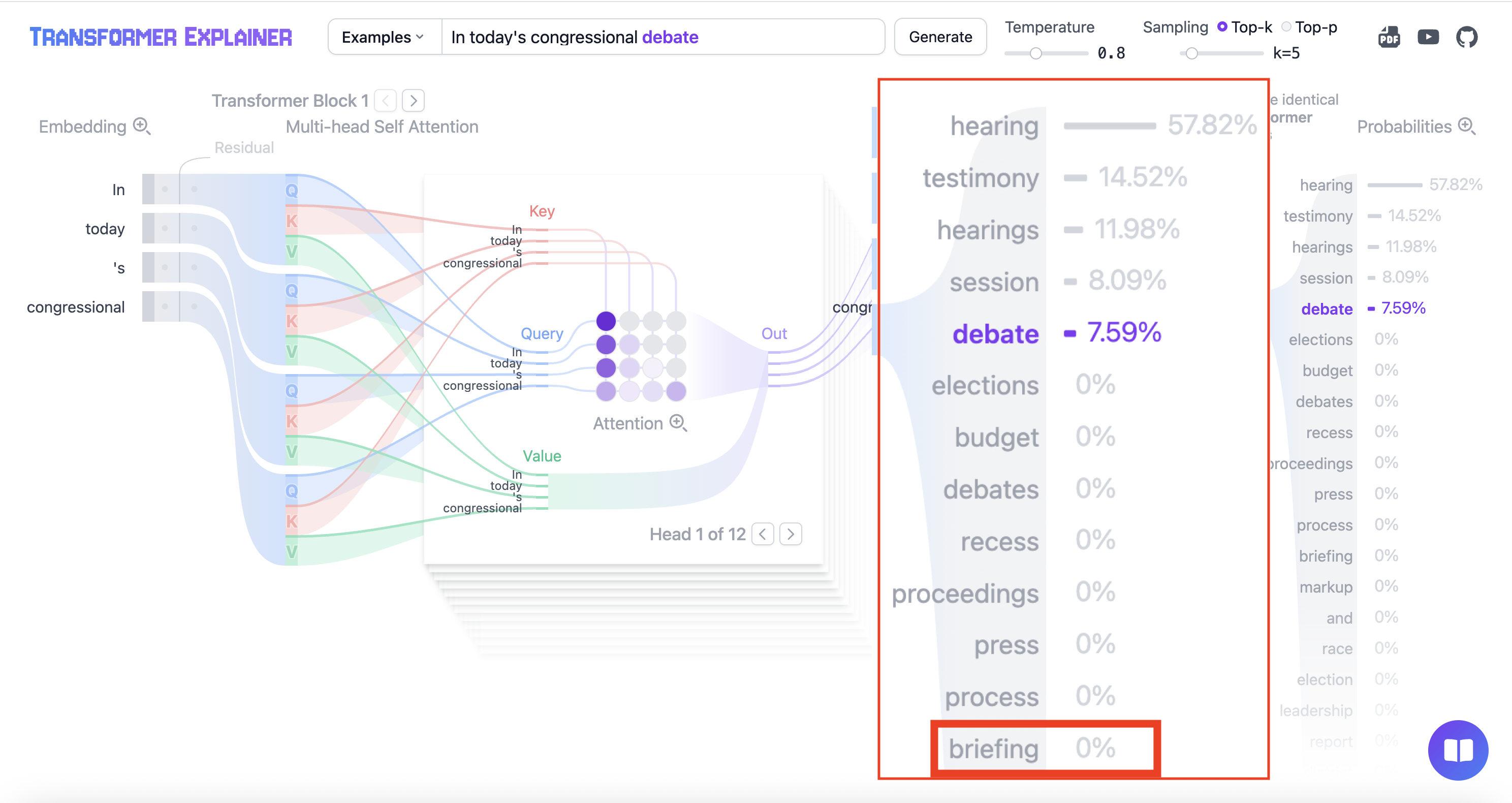
But "briefing" got 0% probability
Lethal Trifecta

Appendix: Reference Frameworks
OWASP LLM Top-10 (2025)
Common vocabulary for vendor diligence and exam readiness
- LLM01: Prompt Injection → Lethal Trifecta, Data Boundary, Security vs. Safety (Sections 3-4, 8)
- LLM06: Excessive Agency → Command Boundary, Tool Scopes, Circuit Breakers (Section 6)
- LLM08: Vector & Embedding Weaknesses → RAG Systems, Tenant Isolation (Section 4, 6)
- Resource: owasp.org/llm-top-10 (2025 PDF)
- How to use: Map vendor controls to LLM01/06/08; demand test results; request red-team reports
NIST AI Governance Stack
U.S. federal anchor for control mapping and measurement
- NIST 2025 Cyber AI Initiative → System-level lifecycle governance (CSF, SP 800-53 cross-walk)
- AI Control Overlays Concept → Map controls to generative/predictive, single/multi-agent systems
- 2025 GenAI Text Challenge → Evaluation structure (Generator/Prompter/Discriminator roles)
- How to use: Request control overlay mappings; ask for AI-BOM and system cards; cite NIST GenAI structure for eval protocols
Financial Services Supervisory Signals (2025)
Bipartisan cover for current-year oversight asks
- OCC Spring 2025 Semiannual Risk Perspective → Operational & third-party risk as GenAI scales
- Federal Reserve Governor Barr (April 4, 2025) → Getting bank risk management ready for GenAI
- CFPB Reg B §1002.9 → Adverse-action reason specificity and traceability (credit use cases)
- SEC (June 12, 2025) → Predictive Data Analytics conflicts proposal withdrawal (investor use cases)
- How to use: Cite in Congressional letters, oversight memos, vendor RFPs to ground asks in established authority
Adversarial & Incident Response Frameworks
Red-team planning and incident coordination expectations
- MITRE ATLAS → Threat-informed AI tactics lexicon (injection, poisoning, evasion, exfiltration)
- SAFE-AI 2025 Report → Control selection approach tailored to AI system types
- JCDC AI Playbook (January 2025) → Federal incident coordination baseline for AI incidents
- CISA AI Data Security Guidance → Data boundary best practices (allow-lists, signing, sanitization)
- How to use: Structure red-team exercises using ATLAS tactics; align incident response plans with JCDC Playbook
Global Alignment & Transparency Frameworks
International standards for capability claims and risk reporting
- OECD AI Capability Indicators (June 2025) → Objective measures for AI system capabilities (task performance, robustness, fairness, interpretability)
- G7 Hiroshima AI Process / OECD Reporting Framework (Feb 2025) → Transparency for advanced AI developers (governance, testing, incident response, public disclosure)
- How to use: Request OECD benchmark results from vendors; ask "Can you fill out the G7 framework?"
- Goal: Avoid conflating marketing hype with measured capability; demand evidence-based assessment
The Lethal Trifecta: 15-Second Risk Diagnostic
☑
Private Data
- Customer PII
- Transaction records
- Account credentials
☑
Untrusted Content
- Open web pages
- Inbound emails/PDFs
- User uploads
☑
Exfiltration/Action
- External API calls
- Outbound email
- Payment initiation
- All three present? → Mandatory containment.
- Kill any one leg → Risk collapses.
Academic References: Scaling Laws and Model Performance
- Kaplan, J., McCandlish, S., Henighan, T., et al. (2020). Scaling Laws for Neural Language Models. OpenAI.
- Hoffmann, J., Borgeaud, S., Mensch, A., et al. (2022). Training Compute-Optimal Large Language Models. DeepMind.
- Brown, T.B., Mann, B., Ryder, N., et al. (2020). Language Models are Few-Shot Learners. OpenAI.
- Bubeck, S., Chandrasekaran, V., Eldan, R., et al. (2023). Sparks of Artificial General Intelligence: Early Experiments with GPT-4. Microsoft Research.
Academic References: Dataset Scale and Diversity
- Bender, E.M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? FAccT Conference.
- Wei, J., Tay, Y., Bommasani, R., et al. (2022). Emergent Abilities of Large Language Models. arXiv preprint arXiv:2206.07682.
- Bommasani, R., Hudson, D.A., Adeli, E., et al. (2021). On the Opportunities and Risks of Foundation Models. Stanford Center for Research on Foundation Models (CRFM).
Academic References: Embedded Knowledge and Unlearning
- Eldan, R., & Li, Y. (2023). Memorization in Transformers: Mechanisms and Data Attribution. OpenAI.
- Yao, Y., Sun, H., Cao, S., et al. (2023). Editing Large Language Models: Review, Challenges, and Future Directions.
- Ilharco, G., Wortsman, M., Hajishirzi, H., et al. (2023). Editing Models with Task Arithmetic.
- Carlini, N., Tramer, F., Wallace, E., et al. (2022–2024). Extracting Training Data from Large Language Models. Google Research.
Academic References: Auditing Training Data and Privacy
- Privacy Auditing for Large Language Models with Natural Identifiers. (2023). OpenReview.
https://openreview.net/pdf?id=jp4XlcpRIW - Perspective: Why Data Subjects' Rights to LLM Training Data Are Not Relevant. (2023). International
Association of Privacy Professionals (IAPP).
https://iapp.org/news/a/perspective-why-data-subjects-rights-to-llm-training-data-are-not-relevant
Academic References: Benchmarking and Scale Effects
-
Wikipedia contributors. (2025). GPT-3. In Wikipedia, The Free Encyclopedia.
https://en.wikipedia.org/wiki/GPT-3 -
Wikipedia contributors. (2025). MMLU (Massive Multitask Language Understanding benchmark). In Wikipedia, The Free Encyclopedia.
https://en.wikipedia.org/wiki/MMLU
Using These Frameworks in Oversight
- Vendor Diligence: Request mappings to OWASP Top-10, NIST overlays, OECD benchmarks, G7 reporting
- Exam Planning: Structure artifact requests around NIST/CISA/JCDC/OCC frameworks
- Red-Team Exercises: Use MITRE ATLAS tactics and SAFE-AI control selection
- Congressional Letters: Cite OCC, Fed, CFPB, SEC supervisory signals for bipartisan authority
- Incident Response: Align plans with JCDC AI Playbook; reference CISA guidance